Justerad xG och Corsi
Sedan jag lanserade den här hemsidan har jag velat göra några justeringar till datat som jag presenterar, närmare bestämt xG-modellen och Corsi siffrorna på lagnivå, och nu när jag har infört dessa justeringar så tänkte jag i den här texten beskriva vad, varför och hur jag gjort detta.
Den rådata som ligger till grund för dessa två är det som samlas in till ligornas hemsidor, live av personer på plats i arenorna under match. Den mänskliga faktorn gör att den här insamlingen inte är 100% konsekvent från arena till arena och eftersom varje lag spelar hälften av sina matcher i sin egen arena så kan det ge ganska stora utslag i statistiken beroende på hur siffrorna taggas. Det här fenomenet kallas ibland "scorekeeper-bias".
Utan att manuellt gå igenom varje avslut och korrigera avståndet, vilket skulle vara i det närmaste omöjligt tidsmässigt, så finns det inget perfekt sätt att åtgärda detta men det finns tekniker för att justera siffrorna så att dom blir mindre påverkade. Den allra viktigaste komponenten i xG-modellen är avståndet till mål när skottet tas. Om en arena konsekvent taggar skotten lite längre från mål än en annan arena kommer det med stor sannolikhet ge utslag i xG-modellen. Det är det här vi vill förbättra.
Jag valde följande metod för att förbättra precisionen; För varje lag tittade jag på genomsnittliga avståndet till mål för alla avslut på hemmaplan och det genomsnittliga avståndet för alla avslut på bortaplan. Differensen mellan dessa två drog jag sedan av från det registrerade avståndet på hemmaplan och använde det nya värdet som input till xG-modellen istället för det registrerade avståndet. På så sätt får vi ett justerat avstånd och här är det viktigt att påpeka att det gäller för båda lagen och inte bara hemmalaget.
Övriga justeringar som jag har gjort har inte med kvaliteten på rådatat att göra utan är av mer hockeyteoretiskt slag för att göra sifrrorna mer prediktiva. Vi använder ju Corsi och xG för att det är bra verktyg för att hjälpa oss förutse hur framtida resultat kommer bli. Det är inte ovanligt att man i sociala medier ser någon ställa upp den faktiska tabellen bredvid t.e.x "Corsi-tabellen" som ett bevis på hur värdelöst Corsi är när två lag skiljer sig åt i dom två tabellerna. För mig blir det ett bevis på att man inte förstår teorin bakom. Om målskillnad och Corsi(eller xG) alltid gick hand i hand så skulle det ju inte finnas någon anledning överhuvudtaget att titta på det. Vi tittar på xG och Corsi för att dom är bevisat bättre än faktiska mål på att förutspå framtida målskillnad. Kommer det alltid stämma? Nej, då behövde vi inte spela kommande matcher, men vi jobbar med sannolikheter.
Det finns några faktorer som dock hjälper dom underliggande siffrorna att bli ännu mer prediktiva. Alla som följer hockey vet att när ett lag hamnar i ledning så är det troligt att det laget kommer bli mer avvaktande och spela "säkrare" för att behålla ledningen samtidigt som det laget som är i underläge kommer gå hårdare framåt för att försöka reducera eller kvittera. Det här kallas för "score effects". På SHL:s och Hockeyallsvenskans hemsida finns en kolumn som heter "Corsi close", som är ett försök att korrigera för score effects. Vad det gör är att ta bort alla avslut där något lag leder med mer än ett mål i period 1 och 2 och alla avslut i 3:e perioden om det inte är lika. Det är dock ett dåligt sätt att lösa problemet på då man tar bort väldigt mycket information genom att kasta bort data. Jag använder istället en metod framtagen av Micah Blake McCurdy, och han hittade att "Corsi close" till och med har sämre prediktivt värde än rå Corsi. (Adjusted Possession Measures)
Micah har en strålande text om sin metod för score-adjustment här Better Way to Compute Score-Adjusted Fenwick, men det går kort ut på att man tittar på historisk data och antalet avslut för lag i underläge och ledning vid en viss ställning i matchen och ger avslutet ett viktat värde utifrån det. Så för ett lag som ligger under med två mål så kommer avslutet att vara värt mindre än för ett lag som leder med 3 mål. Med i beräkningen tas också om avslutande lag är hemma eller bortalag. Hemmalag tar generellt fler avslut än bortalag och på det här sättet korrigerar vi även för det.
En sista ändring jag har gjort gäller xG-modellen och det är att jag har plockat bort blockerade skott från den. Enligt teorin ovan att man inte vill kasta bort data kanske det låter fel men jag noterade att det var endel skillnader mellan arenorna hur blockade skott räknas. Jag kan också filosofiskt tycka att det känns rätt. Där Corsi är en form av proxy för puckinnehav så brukar jag tänka på xG som en proxy för målchanser och att blocka skott är för många lag en viktig taktisk del i att förhindra målchanser, och dessa lag kan bli straffade av en xG-modell som tar med dessa avslut. En annan stor vinning i att ta bort blockade skott är att jag kan avända samma modell för målvakter som jag använder på lagnivå. Tidigare har jag haft två olika modeller där den för målvakter bara har haft med skott på mål men utan blockade skott så kan jag använda modellen även för målvakter. Om man ska ta med missade avslut när man utvärderar målvakter är en liten vattendelare i analyticskretsar, och jag står lite mitt emellan, men tycker tydligheten i att ha samma modell överväger.
Har dom här ändringarna någon effekt då? För att undersöka det så kommer här en kavalkad av grafer som mäter korrelation.
Vi börjar med att kolla på hur konsekventa dom olika mätvärdena är. Det gör vi genom att ta dom två tidigare säsongerna i SHL och dom två tidigare säsongerna i Hockeyallsvenskan och dela varje säsong på mitten och titta på vad första delen säger om den andra delen. Första grafen visar gjorda mål per 60 minuter, den andra grafen visar min tidigare xG-modell och den tredje den "nya" xG-modellen med justerade siffror. Det intressanta att titta på är R-kvadrat värdet som visar på korrelationen mellan första och andra halvan och där ett så högt värde som möjligt är önskvärt.
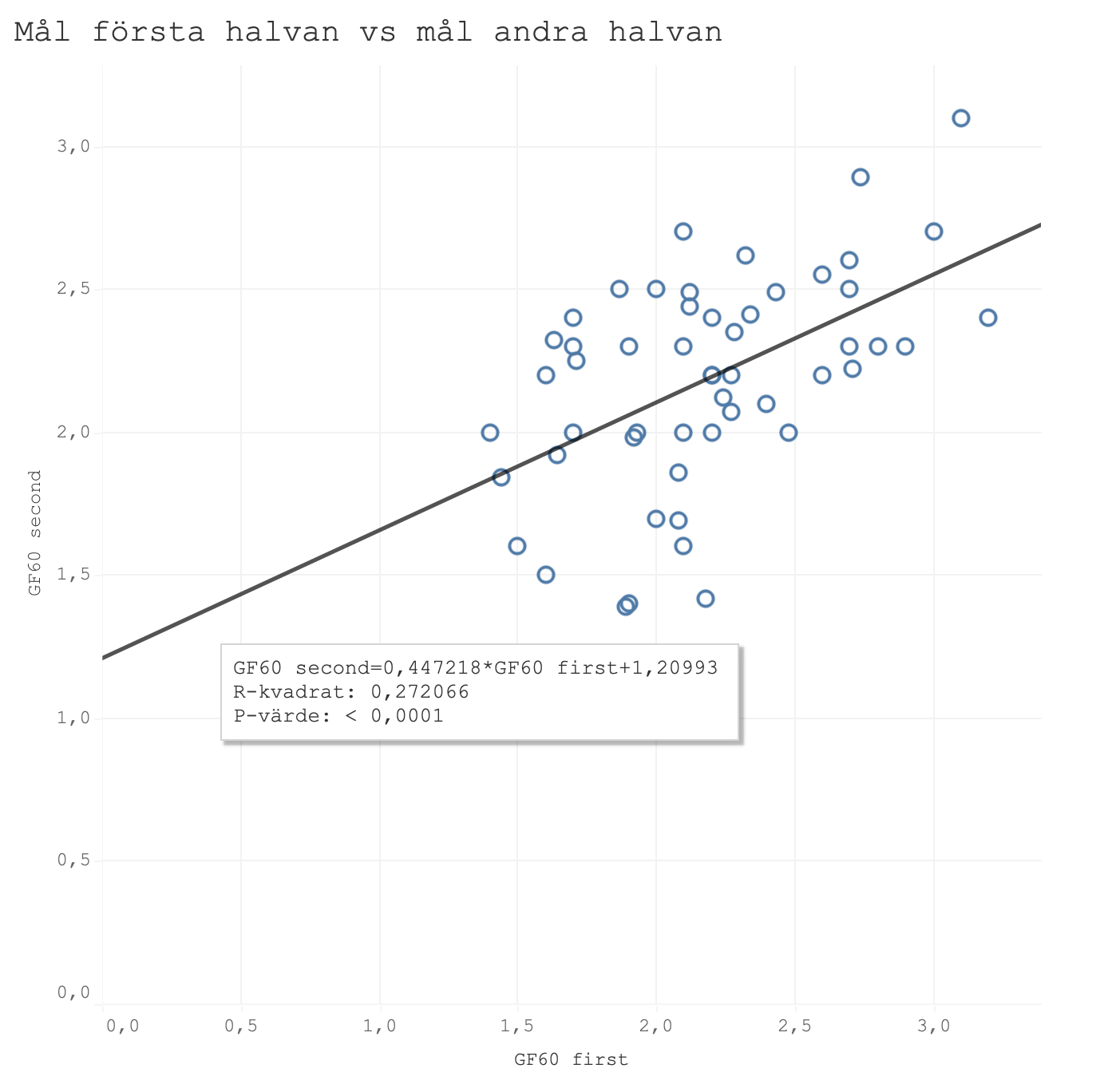
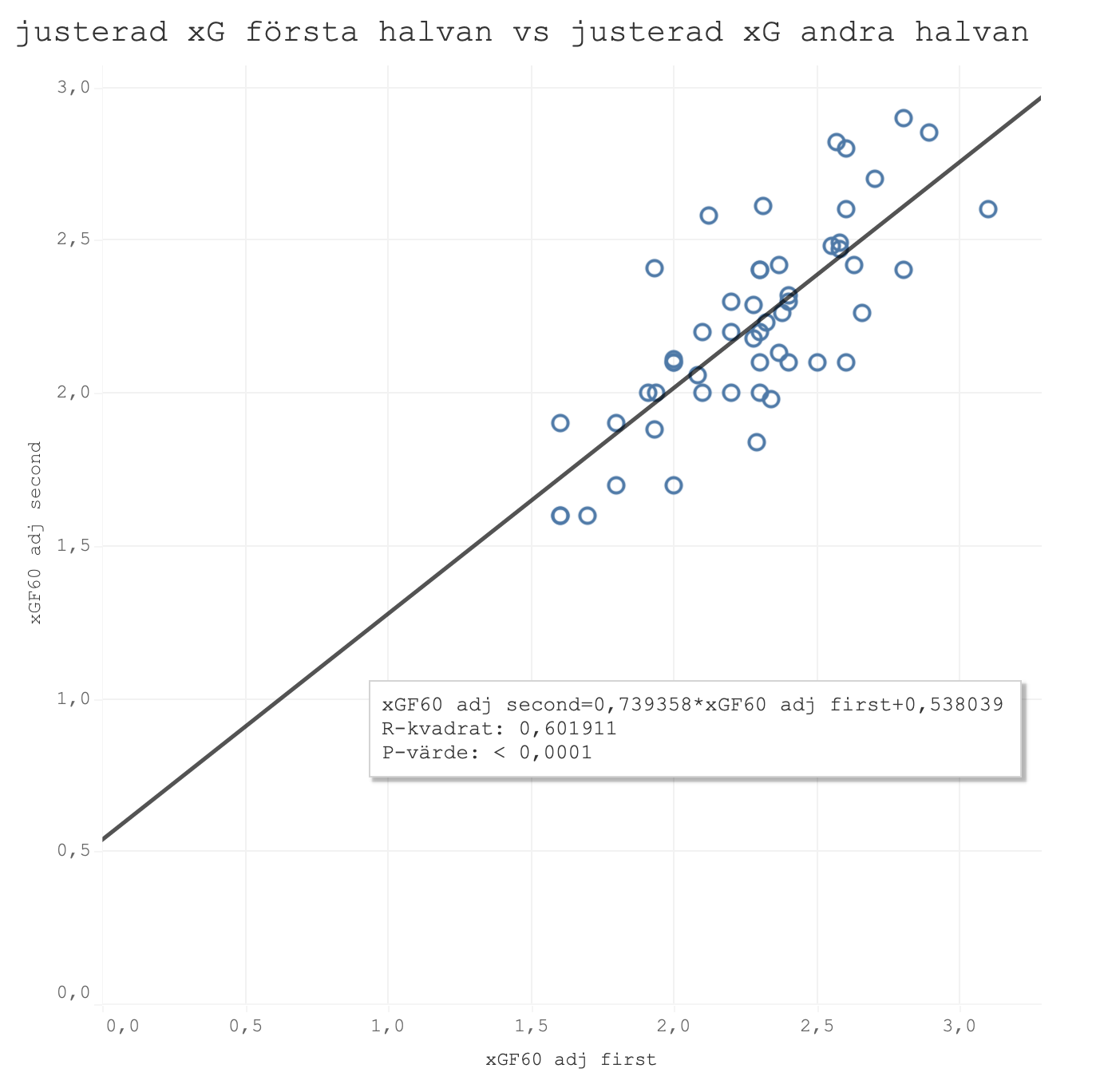
Den tidigare xG-modellen presterar klart bättre än faktiska mål men den justerade modellen presterar bäst.
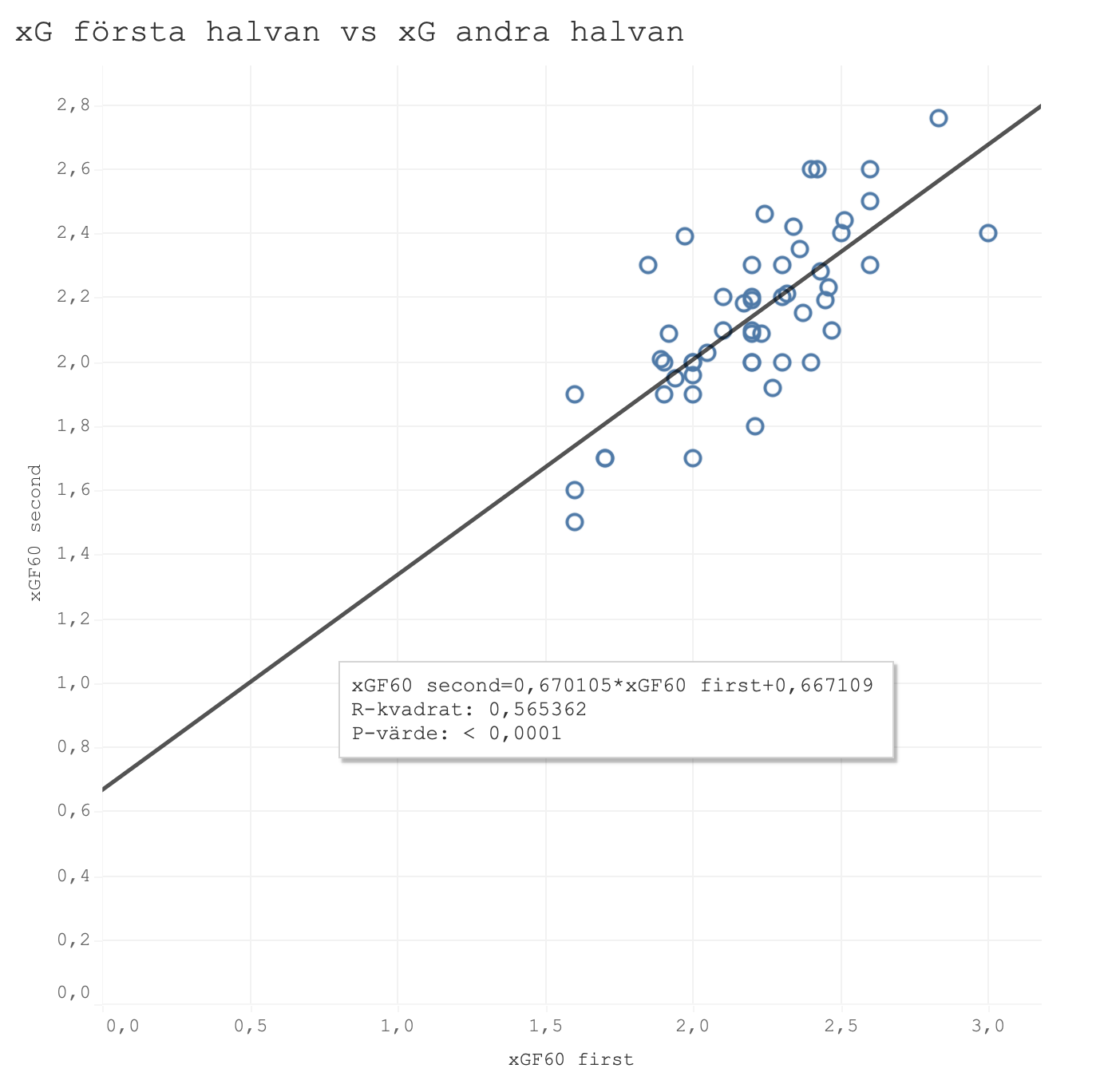
Nu kollar vi på hur första halvan kan förutse gjorda mål under andra halvan. Vi har redan sett att mål hade ett R^2 på 0,27. Graferna nedan visar först den tidigare xG-modellen och sen den justerad modellen.

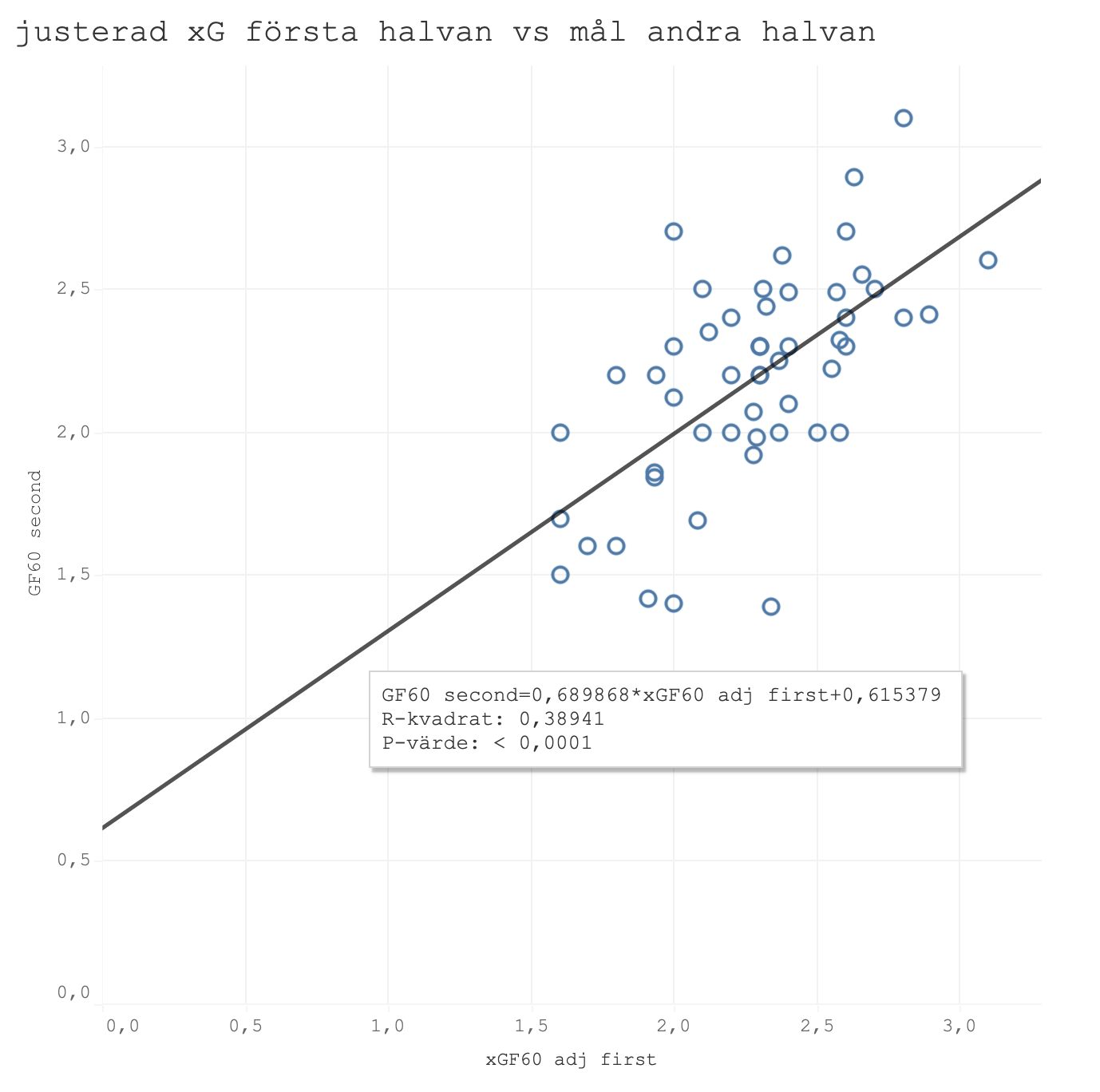
Igen ser vi samma sak. Faktiska mål har lägst prediktivt värde, följt av tidigare xG-modellen och den justerade xG-modellen presterar bäst.
Hittills har vi bara tittat på gjorda mål. För sakens skull slänger vi in samma grafer men för andelen gjorda mål(eller xG) i matcherna, det vill säga även defensiven är medräknat.
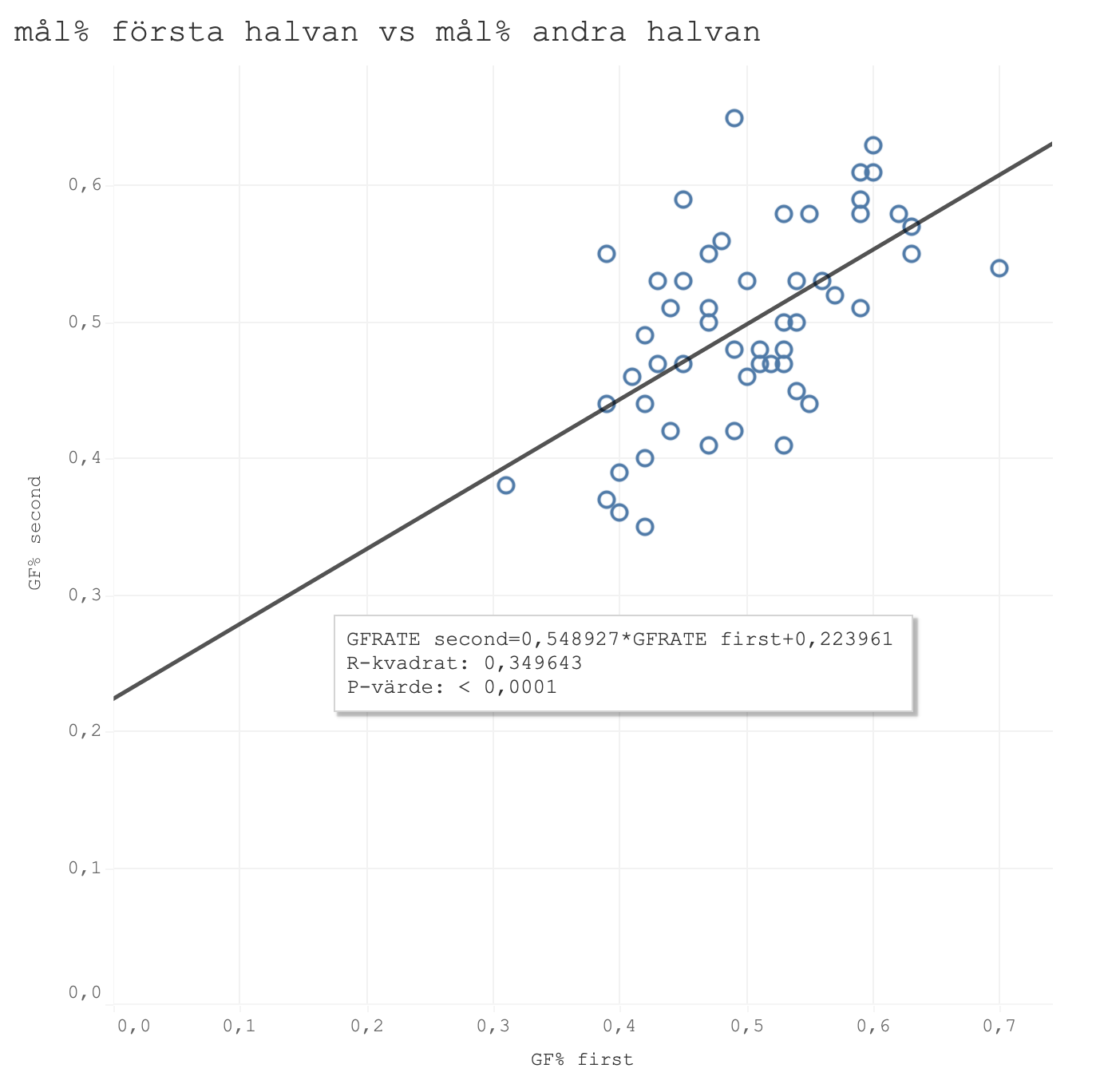
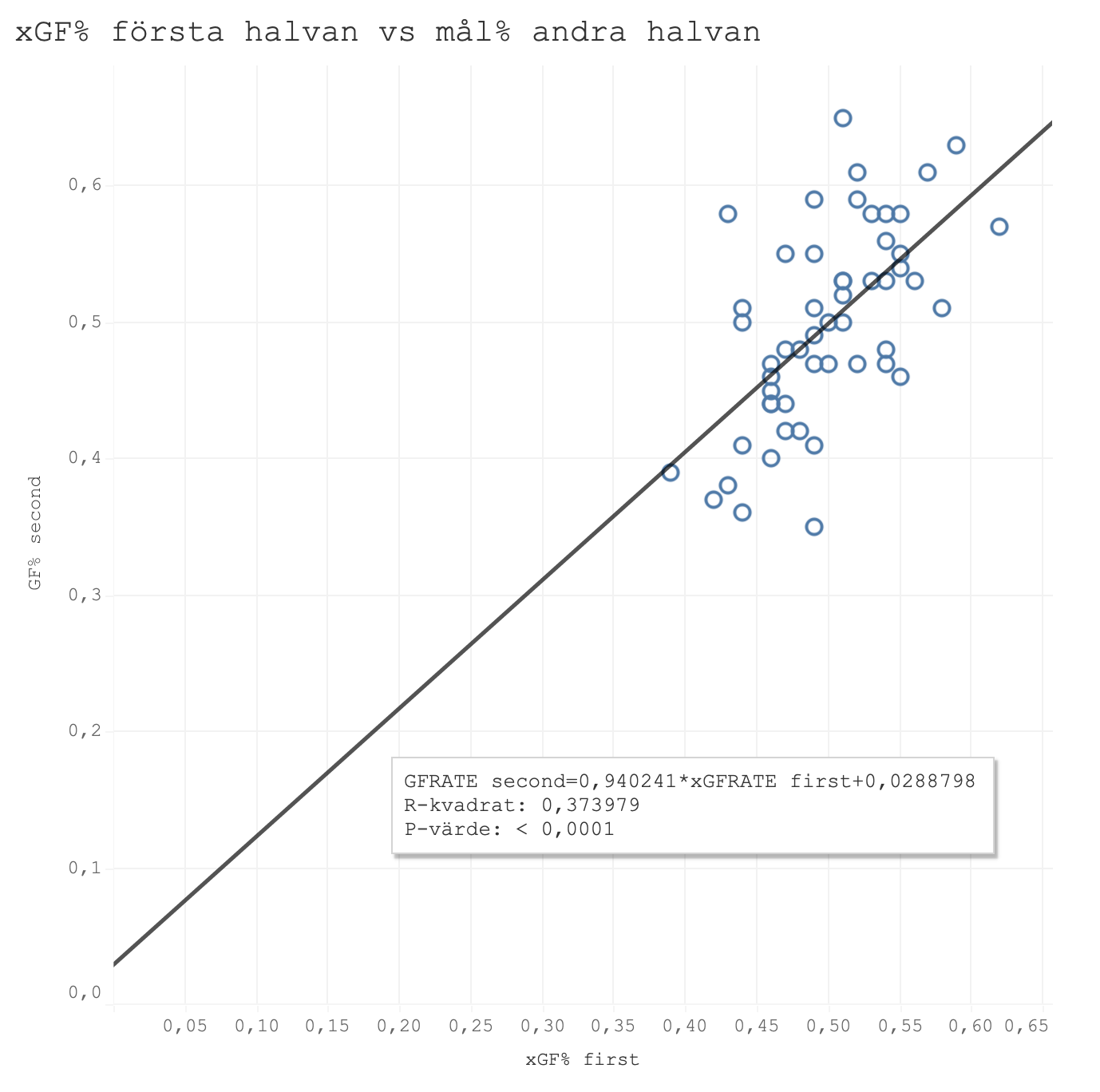
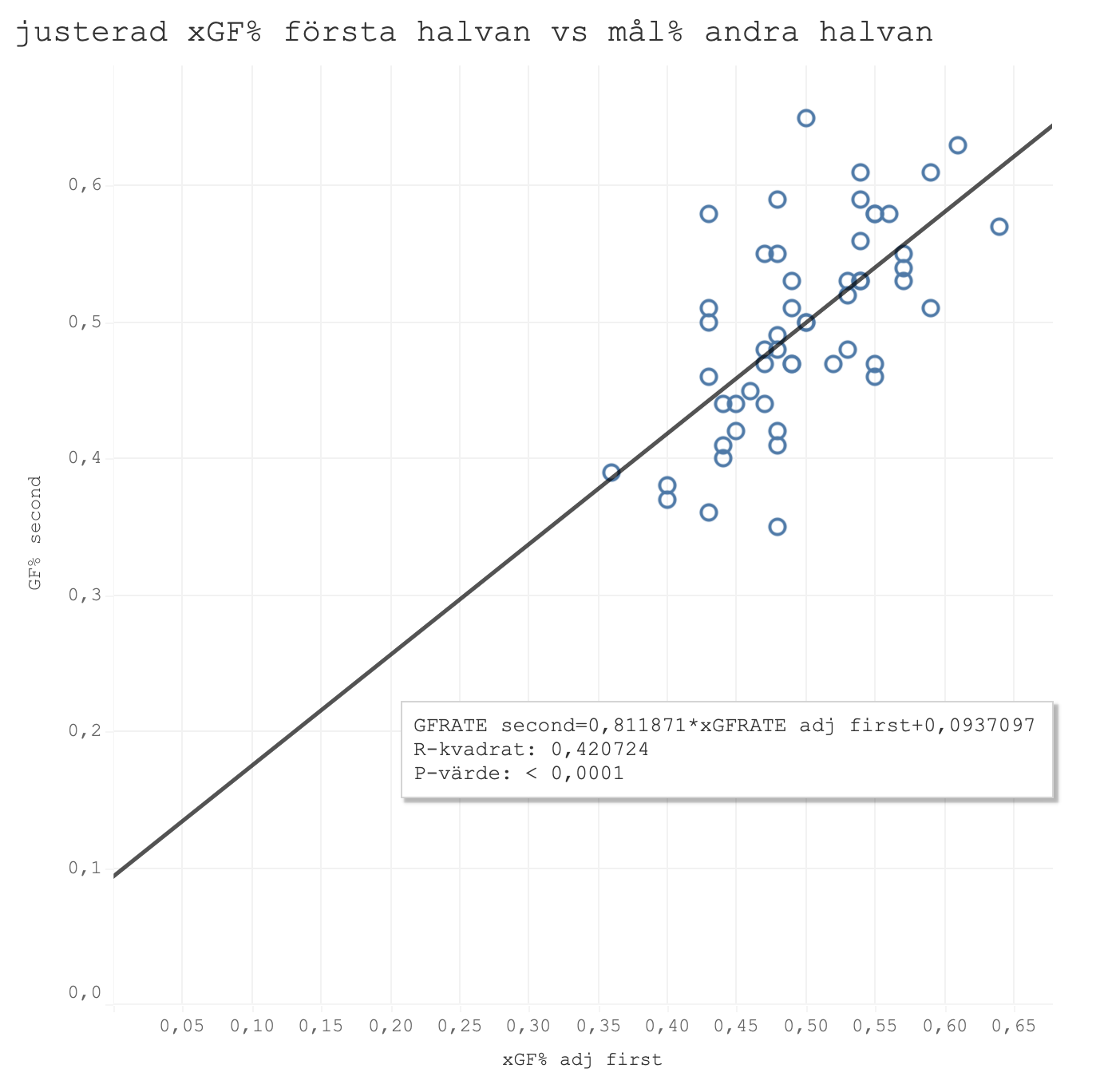
Ännu en gång upprepar sig samma mönster. Den justerade modellen presterade bäst i varje mätning och med gott samvete kan jag byta modell på hemsidan.
Avslutningsvis, jag får ibland frågan varför min xG-modell skiljer sig från sportlogiqs modell(som används av lagen och TV4). I min text om hur jag tagit fram xG-modellen(Hockeysiffrors expected goals modell ) skriver jag lite om ämnet men det kan vara viktigt att förtydliga igen eftersom sportlogiq siffror sprids mer frekvent idag än det gjorde då. xG är inget standardiserat mätvärde, där det är fastslaget vad som ska ingå eller hur det ska beräknas, utan det är ett samlingsnamn som används för att på olika sätt vikta avslut efter hur stor sannolikhet att det blir mål. Sportlogiqs datainsamling är automatiserad vilket innebär att precisionen i var avsluten taggas blir mycket exaktare. Man har också fler events(passningar, ingångar, puckvinster m.m) att tillgå och kan på så sätt få mycket mer kontext kring varje avslut. För NHL finns det många fler kända modeller; Evolving Hockey, Moneypuck, NaturalStatTrick, Sportlogiq, HockeyViz, TopdownHockey, HockeySkytte, ClearSightAnalytics och Stathletes är några av dom och allihop har sina egna inputs och outputs. I Sverige är xG numera närmast synonymt med sportlogiqs modell. Det händer relativt ofta att folk tror att jag t.o.m använder den modellen på hemsidan. Det kan jag säga vore en enormt dålig ekonomisk affär av mig. Men för att sammanfatta, modellerna har helt olika ingångsdata och implementeringen är inte heller densamma men målet med båda modellerna är att vikta avslut efter möjlighet att det blir mål.
Jag har dock fått tillgång till sportlogiqs xG-siffror för SHL och HA den här säsongen så för nyfikenhetens och transparensens skull så gjorde jag en jämförelse med min egen modell. Den första grafen visar xG framåt, den andra visar xG bakåt och den sista xG%.
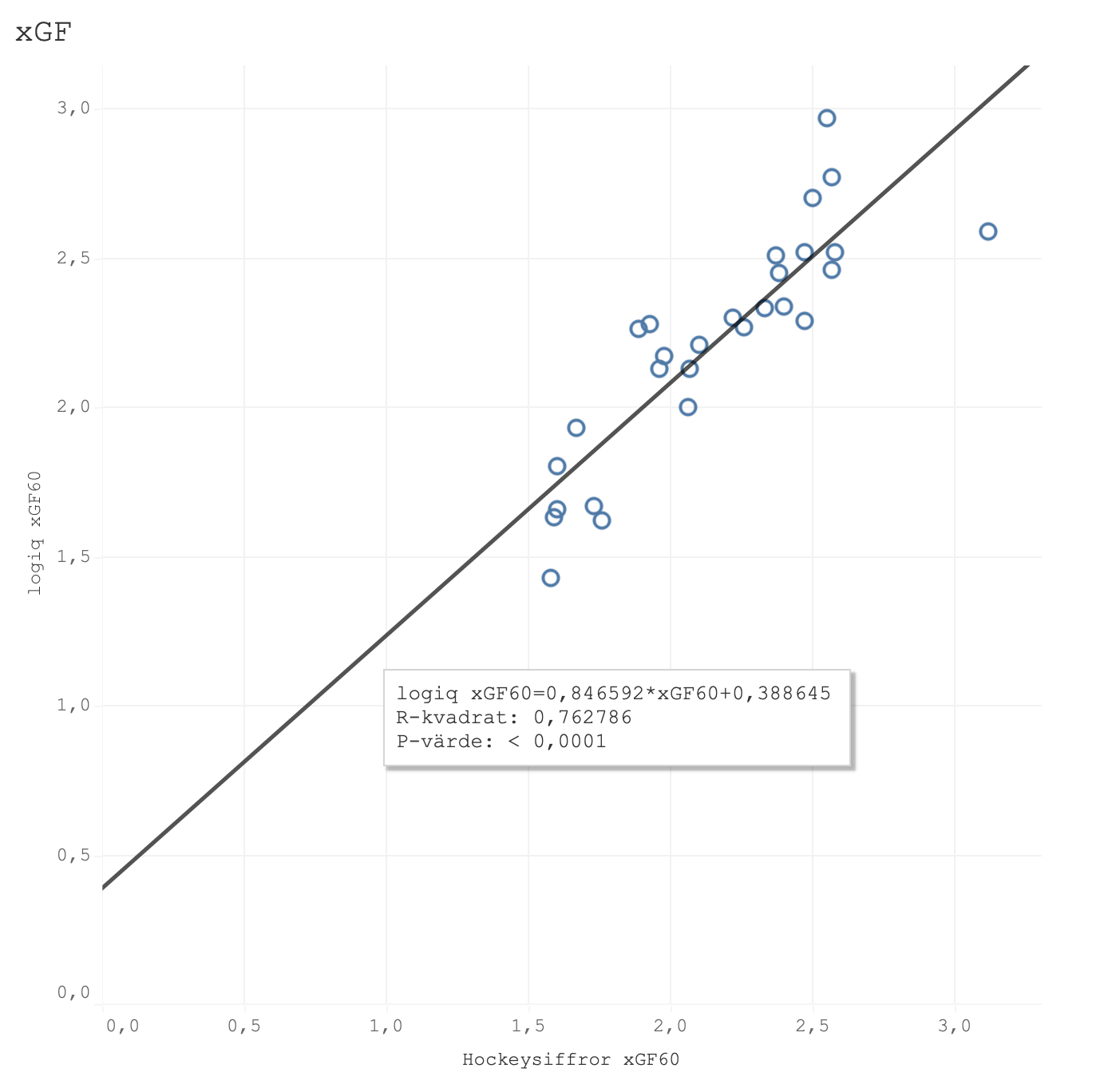
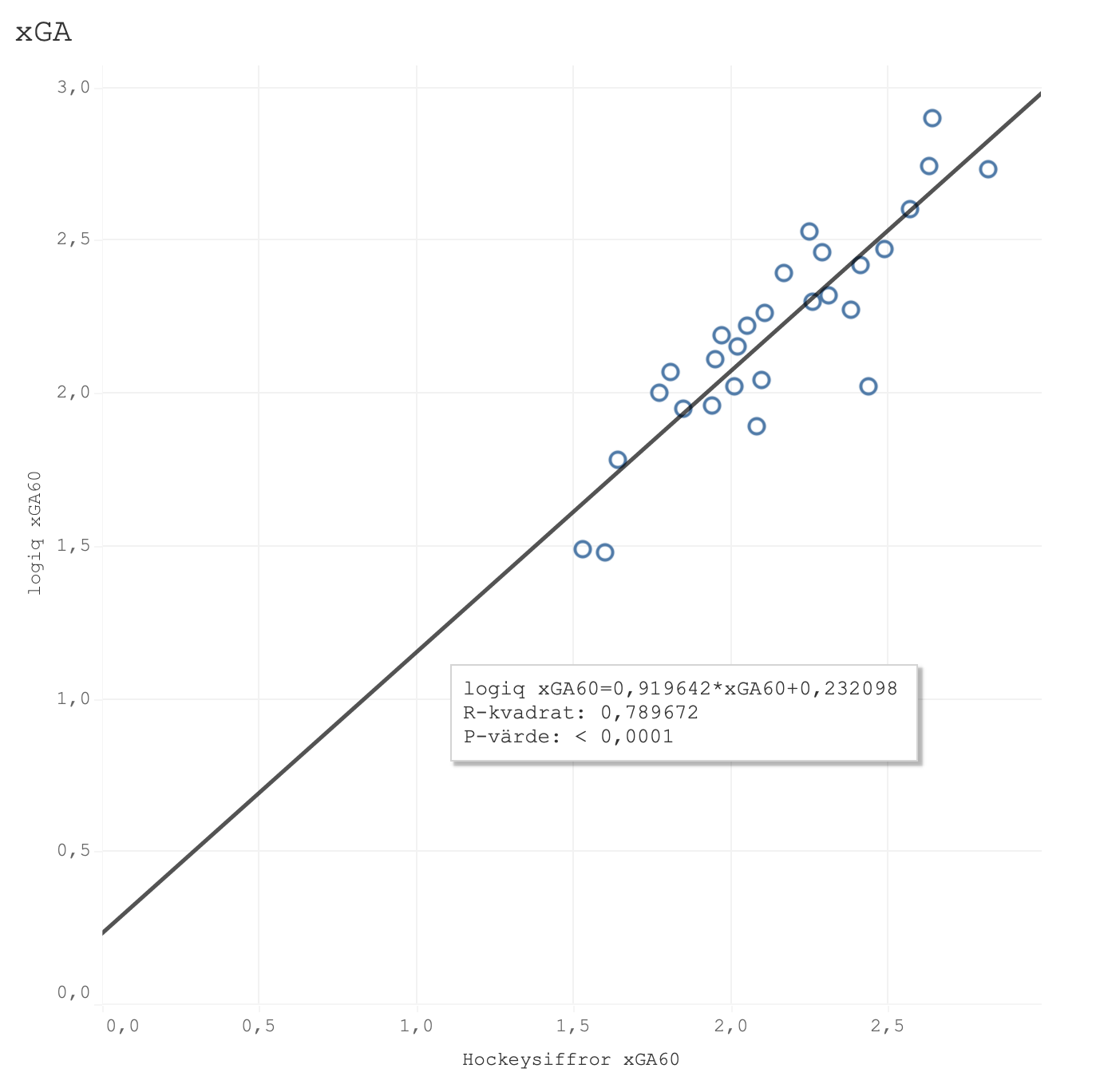
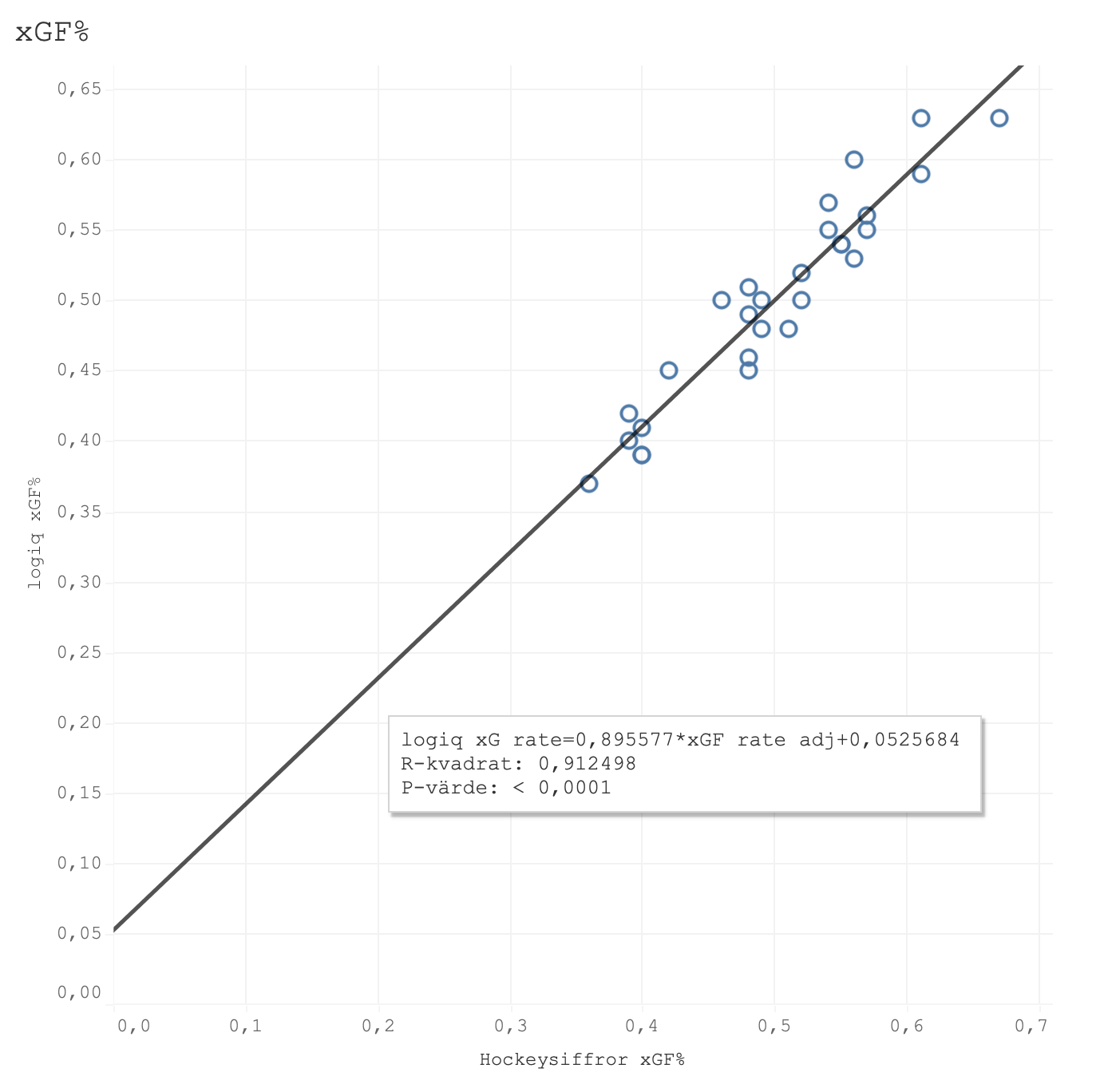
Dom båda modellerna har ett tydligt samband även om det finns outliers när vi tittar på offensiv och defensiv. Tittar man på xGF% som både tar in offensiv och defensiv så är dock sambandet extremt tydligt med en R^2 på hela 0.91. Det här är bara en säsong och således ett litet sample size men intressant att ta med sig. Den här mätningen gjordes för en vecka sen och kan ha skiftat något sen dess men dom två största outliers gällande xGF% var Karlskoga, som min modell håller högre än logiq, och Västerås, som min modell håller lägre än logiq. Jag misstänker dock starkt att det har med min score-adjustment att göra(vilket inte sportlogiq gör till min vetskap i alla fall). Vid tillfället för mätningen hade BIK tagit 49% av sina avslut vid ledning och endast 19% vid underläge medan VIK hade 49% av sina avslut i underläge och endast 16% vid ledning.